URL 与网络资源分享
date
Jun 12, 2019
note
slug
url-and-resource-sharing
type
Post
status
Published
tags
技术
Web
summary
World Wide Web,简称 WWW,中文“万维网”,又叫 Web,而不是 internet 这个只有物理意义的一层。加之如今移动互联网发达,许多刚接触网络的人,对于网络的了解可能仅限于微信、QQ 和各种各样的 APP,已不知道 WWW 为何物。我想应该尝试通过一些简单的语言,理一理其中涉及的概念。
前晚在整理 0xFFFF 的帖子的时候,意外地发现这一篇文:
这篇文其中提到了 internet 和 Web 的概念,引用如下:
中文世界一直混淆互联网(internet)和万维网(web)。人们念兹在兹的「互联网开放精神」,实乃万维网的开放精神。万维网的开放主要就体现在一点:任何万维网上的文章之间都可以通过网址随意互相链接。如果我想在文章里介绍 UbuWeb 这个网站,我就可以直接在 UbuWeb 这六个字母上添加它的网址 ubu.com。妳或许觉得这是废话,但在微信公众号的文章里妳做不到;妳只能添加微信生态圈内的链接,比如这个:
这时候我突然反应过来,我过去其实一直没有区分清楚这里的概念的差别,World Wide Web,简称 WWW,中文“万维网”,又叫 Web,而不是 internet 这个只有物理意义的一层。加之如今移动互联网发达,许多刚接触网络的让,对于网络的了解可能仅限于微信、QQ 和各种各样的 APP,已不知道 WWW 为何物。我想应该尝试通过一些简单的语言,理一理其中涉及的概念。
关于万维网的种种
万维网(WWW),简单地说是一个在互联网(internet)上运行的一个巨型公开资源库。这里的资源可以是文字、图片、视频、音乐、各种文件等等,人们通过开启了 Web 服务的联网的计算机来提供资源,需要资源的人则通过某种方式,利用工具来连接提供资源的计算机,获得对应的资源。
这里所说的某种方式,也就是本文的主题 — URL(通常叫网址、链接)。
获取到的可以直接展示的资源,我们用的最多的是 超文本(Hypertext) 文档,也就是网页。除了基本的文字内容,它的内部可能会包含一些指向其他资源的 URL。这个指向其它资源的部分通常称作超链接(Hyperlink),日常大家都叫它“网址(web address)”、“链接(link)”。
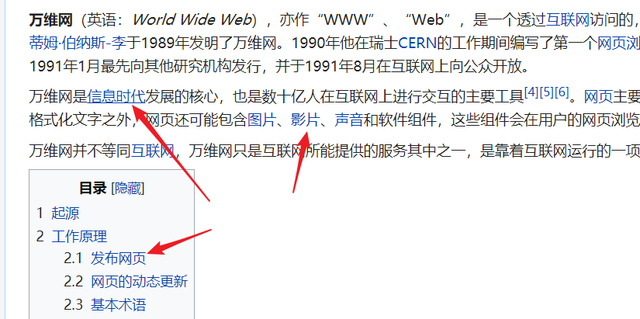
现代网页的源代码(HTML)中超链接被命名为 Anchor,也就是“锚”。脑洞地说,于我们而言,我们上网就像是在在信息的海洋驾驶一艘船,锚便就是船在海洋中的一个个落脚点,在网络的海洋中,船的驾驶速度只发生在0.几秒之间,更多的时间是在抛锚之后的阅读中度过。
一个个超链接之间形成的错综复杂的连接关系,让 WWW 成为了全球最大的信息网络。
万维网毕竟还是依赖计算机,我们作为用户并不能直接访问,这里就有了 Web 浏览器来帮助我们做连接服务器、展示或者下载资源等等工作,作为我们在万维网世界中的代理角色(User Agent)。Web 浏览器做的,也正是通过某个URL,连接到资源的提供者,然后下载展示这个资源。
比如图片中的例子:
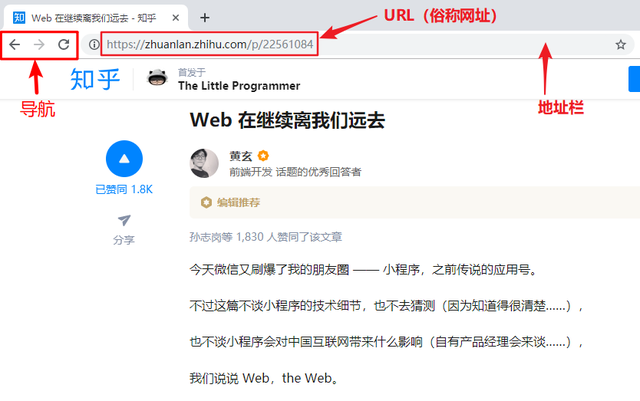
结合前面所说,一个 Web 浏览器在用户可见之处至少包含这三个部分:
- 地址栏:当前展示网页的 URL(网址)
- 导航:后退、前进、刷新、回到主页等等功能
- 展示网页内容的区域
URL是什么?
上面说了这么多 URL 这个术语,也知道它就是网址、链接,那它究竟是个什么呢?这里参考维基百科,做一个简单介绍。
URL,全名为 Uniform Resource Locator,中文名 统一资源定位器,形式上是一小段有特殊意义的字符串。三个字母分别为三个单词的缩写,对应了它的三个属性:
- Uniform: 统一的标准
- Resource: 针对某个特定资源
- Locator: 定位器,也就是获取这个资源的途径和方法
以下是几个简单的 URL 的例子:
对比一下,看似杂乱无章的一串字符之中,你可能会发现一些规律所在,没错,这里的规律,设计者最初是这样定义的:
URL = scheme:[//authority]path[?query][#fragment]
各个部分的解释如下:
- scheme: 资源的请求方法(使用的网络协议)
- authority: 关于需要请求的提供者的服务器的地址、端口信息
- path: 资源在提供者的服务器的路径
- query: 针对这个资源的查询参数
- fragment: 查询片段
其中,
[] 内的内容是可选的,也就是说,并不需要所有部分都满足,可能只有 scheme:[//authority]path 这部分。服务器(authority)信息具体是这么定义的:
authority = [userinfo@]host[:port]
日常我们能看到最多的是其中的 host 部分,它可能是
www.baidu.com 这样子的域名,也可以是 202.115.72.8 这样的 IP 地址,偶尔可能会有 port 这部分。关于 URL 更详细的定义,参考 RFC 3986 - Uniform Resource Identifier (URI): Generic Syntax。
URL 的例子
下面举一些 URL 的例子,熟悉下这里的定义。
首先我们看这个:
https://cs50.harvard.edu/college/2019/fall/guide.pdf
这个 URL,其中包含的信息点分别是:
元素 | 信息 |
https | 这个资源的获取过程遵循 https 协议 |
cs50.harvard.edu | 通过 cs50.harvard.edu 所指向的服务器获得资源 |
/college/2019/fall/guide.pdf | 这个资源在服务器的具体路径是 /college/2019/fall/guide.pdf |
再举两个例子:
- ftp://ftp.freebsd.org/pub/FreeBSD/
元素 | 信息 |
ftp | 这个资源的获取过程遵循 ftp 协议 |
ftp.freebsd.org | 这个资源是通过 ftp.freebsd.org 所指向的服务器获得的 |
/pub/FreeBSD/ | 这个资源在服务器的具体路径是 /pub/FreeBSD/ |
- http://202.115.72.8/dzzn.htm
元素 | 信息 |
http | 这个资源的获取过程遵循 http 协议 |
202.115.72.8 | 这个资源是通过 202.115.72.8 所指向的服务器获得的 |
/dzzn.htm | 这个资源在服务器的具体路径是 /dzzn.htm |
浏览器内部得到地址栏输入的 URL,将这串字符分解,得到以上说的请求方法、服务器地址、路径等信息点,然后按照协议的请求方法,连接上这里描述的服务器地址,然后按照路径请求下载对应的资源。
一般来说,为了方便记忆,很多时候上网只需要记一个域名,剩下的请求方法、路径什么的浏览器会自动帮我们补全,比如说,我们在浏览器输入
qq.com,实际上浏览器会自动补充 http://qq.com/ 这个完整的 URL,然后再访问目标,再跳转到合适的 URL 打开内容。正是浏览器和服务商们都遵循了这个统一的标准,简单几个字母和符号,就可以把我们带入一个个精彩纷呈的信息世界。
分享 URL 的姿势
一般来说,分享一个网络资源,我们只需要把它的 URL 复制出来,然后直接粘贴发送给想分享给的对象即可,基本过程虽简单,但背后还是蛮多细节值得留意。
去除不必要的参数
如今许多手机APP,在打开链接的时候,会在其背后加上某些参数,方便统计和跟踪之用。另一方面,这些参数带来了复杂和不美观,乃至于可能存在隐私泄露,被跟踪的风险。
比如说,微信分享的链接,一般会加上类似
?from=groupmessage&isappinstalled=0 这样的查询参数,它的存在并没有必要,所以分享的过程中可以直接去掉这一部分。再如,网易云音乐分享的链接,会包含一个 userid 的字段,通过 userid 参数,我们可以立刻定位到分享这首歌的用户。
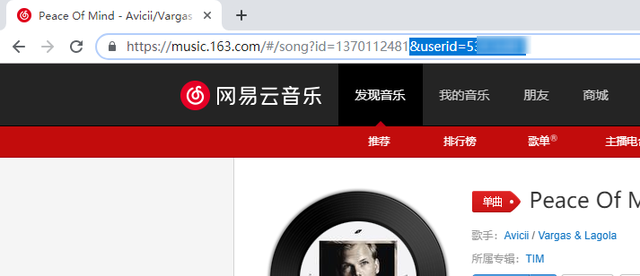
一般来说,我们可以利用浏览器测试修改后的链接,避免去掉某些重要参数以后出现问题。
摘要的重要性
考虑到URL的资源需要从资源提供方的服务器中获取,网络环境的复杂,网页开发质量的参差不齐,移动互联网的弱网环境等等因素,对方点击打开一个 URL 的过程就可能出现许多不确定的情况,无形中可能增加许多的时间成本。基于此,对方收到这个 URL,如果在点开之前能提前快速知道一些关于这个 URL 背后的资源的一些简单介绍的话,这里的分享会友好很多,节约对方判断是否值得一看的时间成本。所以这里涉及到了一个摘要、快速预览的需求。
举个例子,假如你收到这样的链接,没有任何的上下文:
一眼望去,会不会有点懵逼感觉?如果我们在前面给它一个比较简短的一句话介绍,比如说对应页面的标题:
Web 在继续离我们远去 - 知乎有没有什么软件适合写写东西的? - 知乎https://www.zhihu.com/question/267397696/answer/325352426URL连接之所见(Java) - 0xFFFF https://0xffff.one/d/292/4
是不是清晰了许多!
btw: 如果你平时有细心留意,你也许会留意到有的网页的 URL 是包括了网页的标题的,比如说 StackOverflow, Quora 之类的网站中的问题页:
可以发现,URL的本身就能够包含一些摘要作用的信息,但由于URL本身只支持 ASCII 字符,在表示其它的语言的时候,需要进行 urlencode 编码,这样的操作也仅仅是在英文世界通用。
在中文世界类似这样:
一堆的百分号混在一起,基本丧失了可读性,然后又回到了摘要的问题。
自动生成摘要
一般来说,一个设计良好的 Web 页面本身会提供摘要和关键字等信息,我们在一些程序分享 URL 时,程序会自动抓取关于这个 URL 的摘要信息,甚至还可以直接预览全文,方便用户快速确定这个资源的基本情况。
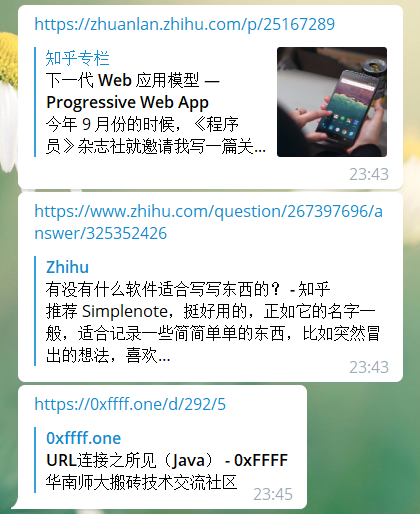
一般的社交网站会提供一些特殊的功能标签,类似微信的 JSSDK 的分享设置,脸书的标签等等,网页开发者可以针对特定平台产生合适的摘要。知乎在粘贴链接的时候也会自动获取目标页面的标题。
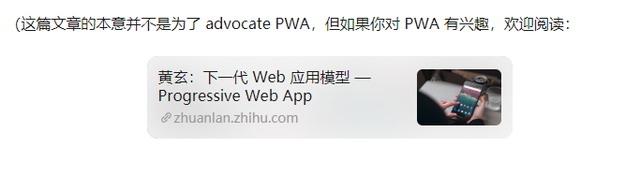
但在国内的人文环境和大众的网络素养等种种因素,也决定了一下子开放的思维并不是很行得通,绝大多数时候,这个选项存在着门槛,大部分的网站在微信中并不会有比较好的摘要表现。
在微信的体系中,体验最好的,也就只能是微信公众号这类自家平台了,实际上,转发到微信的公众号文章的背后,也是一个 URL,只是被微信有意地隐藏了起来,微信公众平台也对摘要这样的操作做了一些可视化的要求:
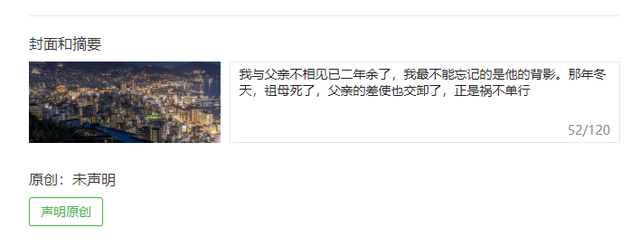
在这门槛之下,对于外部的 URL,在粘贴之前,尽可能做一小段详细介绍会比较好。实际测试之下,感觉效果还是很不错的,QQ 与微信都会对 URL 进行高亮操作,然后变的可点击。
为了方便产生这样的摘要,根据我之前的实践,有一个名为 TabCopy 的 Chrome 插件,可以实现一键复制网页标题和链接,快速实现链接摘要的需求。
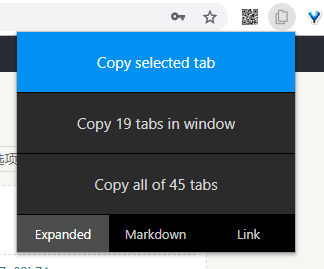
甚至还能多标签页批量复制链接:

图片海报形式分享
图片具有方便制作(只需简单截屏),传播效率极高的属性,在 4G 时代,图片发送在速度上和到达率上已经接近于文字,流量消耗相比于视频可以说是九牛一毛。一定程度上可以用来解决部分内容的快速预览的问题(类似早期的长微博)。
但这里的缺点是,一张发出去的图片就像一张印好的传单,若只有内容而无任何标记,追溯来源就变得十分困难。就算有标记,字符的标记的转换过程更多依赖于手动输入,对于 URL 这样的相对较为复杂又要求准确的数据,手动输入并不友好。
在这个需求下,很容易想到二维码这个载体,对于基于图像的信息转移的需求,二维码读取非常快速又准确,可以把许多 URL 背后的对于人类的复杂隐藏起来。如今移动设备十分方便的扫码功能,以及类似微信、QQ 的长按识别二维码的方式,无疑是一个很好的助力。
这里的制作方式也超级简单,只需要截图,然后生成这个 URL 对应的二维码,拼起来即可,用著名截图工具 Snipaste 可以很快速地完成这个过程。
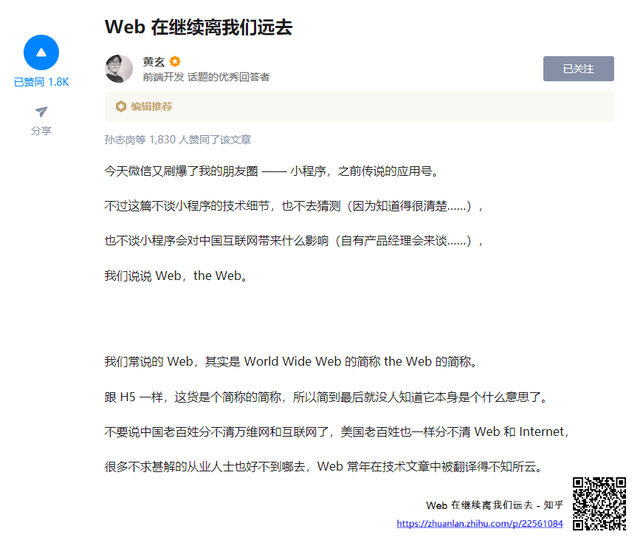
这一招在朋友圈、微信推文分享可以说是屡试不爽,微信读书、网易云音乐、豆瓣等都做的很好。

我们可以留意到,微信读书和网易云音乐分享出来的东西,仅仅只展示了二维码。二维码背后实际上还是 URL,同样可能存在隐私跟踪参数、钓鱼链接等不可控的风险。
URL本身有可能从域名的可信度,路径和参数看出其中可能存在的问题,而二维码的形式,我们是完全无法下意识感知出那些细微的差异和隐藏的信息,所以我认为,扫码工具在获得二维码背后的 URL,尽可能在图片中展示一个完整的 URL 也是有必要的,打开之前,应该对不明的 URL 有所提示。
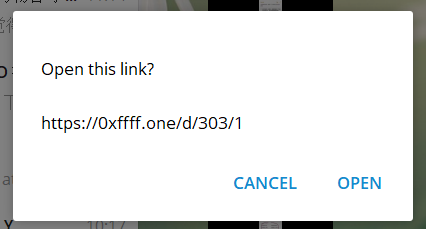
微信并没有做到这一点,而是把这个本应用户自行验证的过程悄悄地交给了并不完全可靠的“网址安全检测”,黑灰产们不断地研究如何绕过,腾讯的安全中心不断与之较量,在这愈演愈烈的战斗之下,防线不断加强,许多原本正常的域名也被一刀切,带来的是无尽的资源浪费。
二维码的本质,就像超市商品的条码、书籍的 ISBN 条码一般,只是一个辅助输入的工具,并不能完全取代 URL 的一切。在二维码普及的今天,若不普及 URL 的知识,人们对于二维码背后是啥漠不关心的话,强调再多的“别扫”、“别点”、“别接”,带来的更多的还是因噎废食。
做好预览海报分享这一块的体验的关键,需要在平面设计方面多下一些功夫。设计一批通用而舒适但又不失对用户的知情权和隐私的尊重、还能激发探索的好奇心的海报模板和辅助生成预览海报的程序,会是一件非常有意思的事情。
写在最后
万维网的种种属性,也意味着它更适合那些开放、长存的知识的链接和分享。作为知识工作者,我们自然不能忽视万维网的存在,网络中的那些能持续沉淀的,往往也只能长久存在于万维网中。
只是,在我们的身边,地区的不平衡、教育本身的不健全、在商业的推动下过于高速发展的科技与大众较低的文化水平两者之间的矛盾也愈演愈烈。结果便是商业的平台攻略了这里的知识盲区,早早地做了一层带着利益外衣的不可靠抽象。
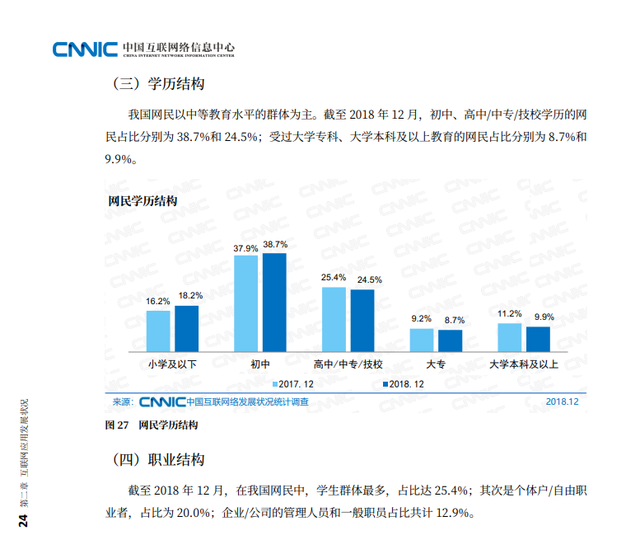
参考 CNNIC 的数据,想象一下,大学本科以上仅占人口的 10% 左右,就算是我所在的所谓“211”大学的计算机学院,能清晰地体会到 Web 概念的人也寥寥无几,更何况更广大的国民?
在这背景之下,微信也正是在这有着巨大差异的国人的沟通需求之间权衡、妥协后的产物,无形中承担了许多数不清的本应每个人独立承担的责任(例如,腾讯游戏的“成长守护平台”),背后也存在着许多善与恶、良币与劣币之间的斗争。
这个世界有很多 shit,这是我们无法避免的,shit 要一点点铲掉,而人们能否始终保持着一颗向善的心而不迷失在那些 shit 之间,也是一个问题。不过也有理由相信,构建起整个科技世界的根基,是知识、是实打实的技术,并不是商业寡头们的金钱利益需求。那些妥协和封闭起来的事物,在短视的利益面前,当它失去了所谓流量关注和商业价值以后,也将随之陨落。一直蒙蔽双眼,处于偏离事物本身的状态,也就意味着长远来看,他们走不到第一梯队。
前段时间有看到这个帖子:从寻找 qq20 周年活动链接,看互联网分享精神的退化 - V2EX
实际上,人们的分享精神还在,只是如今许多的平台的门槛做得很低很低,那些还不知 Web 为何物的人们,在方便面前,失去了跨越门槛的动力,Web 也渐渐地式微。我们能做的,大概也是认清这些平台的妥协本质,在我们力所能及的范围内用更好的方式来表达和分享自我。
那么,就让我们在网上的分享,从认识和更好地使用 URL 开始吧!